Pruebas
de la bondad de ajuste.
La bondad de ajuste de un modelo describe lo bien que se
ajusta un conjunto de observaciones. Las medidas de bondad en general, resumen
la discrepancia entre los valores observados y los K valores esperados en el
modelo de estudio. Tales medidas se pueden emplear en el contraste de
hipótesis, el test de normalidad de los residuos, comprobar si dos
muestras se obtienen a partir de dos distribuciones idénticas ( test de
Kolmogorov-Smirnov), o si las frecuencias siguen una distribución específica
( chi cuadrado).
Si el analista desea conocer el comportamiento, es necesario
modificar la forma de presentación de datos y presentarla como tablas de
frecuencia, con la finalidad de realizar cualquiera de las siguientes pruebas:
* Prueba de bondad de ajuste X2
* Prueba de Kolmogorov-Smirnov
Prueba
de bondad de ajuste X2
Esta
prueba se utiliza para encontrar la distribucion de la probabilidad de una
serie de datos.La metodologia de la prueba X2 es la siguiente:

1.Se colocan los n datos historicos en una tabla de frecuencias
de
intervalos, Se obtiene la frecuencia observada en cada intervalo i(FOj).
Se calcula la media y la variancia de los datos.
2.
Se propone una distribucion de pobabilidad de acuerdo con la forma de la
tabla de frecuencias obtenida en el paso 1.
3.
Con la distribucion propuesta, se calcula
la frecuencia esperada para cada uno de los intervalos (FEi)
mediante la integracion de la distribucion propuesta y su posterior
multiplicacion por el numero total de datos.
4.
Se calculo el estimador:
5.
Si el estimador C es menor o igual al valor correspondiente X2
con m-k-1 grados de libertada (k= numero de parametros estimados de la
distribucion) y a un nivel de confiabilidad de 1-α, entonces no se puede
rechazar la hipotesis de que la informacion historica sigue la distribucion
propuesta en el punto 2.
Mediante la prueba X2 determine el tipo de
distribución de probabilidad que sigue la demanda de automóviles a un nivel del
95%, si a través del tiempo se ha registrado el comportamiento consigna en la
figura 1.13.
Obtenga la tabla de frecuencias d la figura 1.13
considerando 7 intervalos y cauntificando la frecuencia para cada uno de ellos:


La distribución de probabilidad esperada que se propone,
observando los datos de FO, es una distribución uniforme
entre a = 0 y b = 13 y automóviles por día, o
sea:
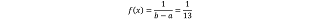



Integrando la
función:
Donde:
LI:
Limite Inferior de cada intervalo.
LS:
Limite Superior de cada intervalo.
Sustituyendo valores para obtener F(x) y
multiplicándolos por es total de datos, se obtiene FE para cada intervalo.

Calculando el estadístico C con los datos FEi
y FOi se obtiene:
C=4.092
El
valor C=4.092, comparado con el valor de la tabla X5%,6=12.59,
indica que no podemos rechazar que los datos anteriores se comportan de acuerdo
a una distribución uniforme entre 0 y 13 automóviles demandados por día con un
nivel de confianza del 95%, entonces:
Demanda=
U (0,13) automoviles/dia
Prueba de Bondad de Ajuste de Kolmogorov-Smirnov
Si
el objetivo es encontrar el tipo de distribucion deprobabilidad de una serie de
datos, esposible utilizar la prueba de bondad de ajuste de Kolmogorov-Smirnov,
la cual, comparandola con la de X2, es mas eficiente en varios
aspectos ya que trabaja con la distribucion de probabilidad acumulada. La
metodologia es la siguiente:
1. Se colocan los n datos históricos en una tabla de frecuencias
con nidsks. Para cada interval o se tendrá la frecuencia observada i (FOi). Se
calcula la media y la varianza de los datos.
2.
Se divide la frecuencia observada da cada intervalo por el
número total de datos a este resultado, para obtener la probabilidad
observada(POi).
3.
Se calcula la probabilidad acumulada observada de cada
intervalo (PAOi) del paso 2.
4.
Se propone una distribución de probabilidad de acuerdo con la
forma de la tabla de frecuencias obtenida en 1.
5.
Con la distribución propuesta se calcula la probabilidad
esperada para cada uno de los intervalos (PEi).
Mediante la integración de la distribución propuesta.
6.
Se calcula la probabilidad acumulada esperada (PAEi) para cada intervalo de la clase.
7.
Se calcula el valor absoluto entre PAOi y PEOi para cada
intervalo y se selecciona la máxima diferencia, llamándola DM
8.
El estimador DM se compara con el valor límite
correspondiente con n daos y a un nivel de confiabilidad de 1-α . Si el
estimador DM es menor o igual al valor límite de la tabla en función del nivel
de significancia y del tamaño de la muerta, no se puede rechazar que la
información histórica sigue la distribución propuesta en el paso 4.
Ejemplo:
Mediante la prueba de Kolmogorov determine el tipo de
distribución de probabilidad que siguen los datos del ejemplo anterior, con un
nivel de confianza del 95%. Obtenga la tabla de frecuencias, considerando 7
intervalos:

La distribución de probabilidad esperada que se
propone, según los datos de la columna FO, es una distribución uniforme entre 0
y 13 automóviles por día, o sea:
Integrando la
función:
Donde:
LS:
Limite Superior de cada intervalo.
Evaluando
la ecuacion anterior, se obtiene la tabla siguiente:

Al
obtener la diferencia término a término entre PEA y POA, se tiene:

El
valor DM es igual a la máxima diferencia, o sea 0.0694, que comparándolo contra
el valor de d5%,41=0.2123 indica
que los datos anteriores siguen una distribución uniforme entre 0 y 13
automóviles demandados por día, con un nivel de confianza del 95% por lo tanto:
Demanda=
U (0,13) automoviles/dia
Bibliografía
Reza
M., García E. (1996). Simlulación y análisis de modelos estocásticos. México:
MacGraw-Hill.
No hay comentarios:
Publicar un comentario